Effortlessly Consolidate Data into Your Data Lake
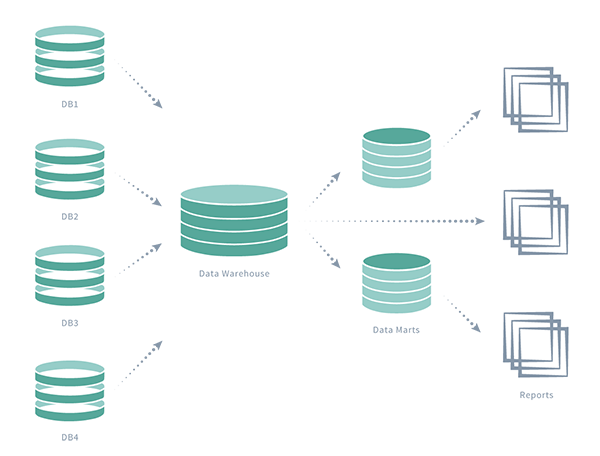
More organizations are adopting data lakes as part of their architecture for their low cost and efficiency in storing large volumes of data. The idea is simple: Instead of storing data in a purpose-built data store, you move it into a data lake in its original format. This eliminates the upfront costs of data ingestion and transformation. Once data is in the lake, it’s available to everyone in the organization for analysis.
But while a data lake is an efficient solution, it does not come without challenges:
- Initial on-boarding of data from multiple sources
Continual updates in real-time
Moving high volumes of data to the data lake while mitigating chatter and latency
We enable you to easily move your data into your lake and update your data lake in real-time. HVR’s solution includes:
- Initial data load from multiple sources to the data lake
- Log-based change data capture for real-time updates
- Compare and repair feature to ensure data accuracy
Benefits of using HVR to feed your data lake include:
- Efficiently load and update data
- Move high volumes of data for real-time analysis
- Accelerate data movement with minimal impact on systems
- Scale the solution for multiple projects and systems
Native Hive Support
The data lake is typically the initial landing zone for the data. Data scientists commonly use access to the data lake to identify data sets of interest in order to slice-and-dice the data in a different, more suitable, high-performance analytical engine. Native Hive Support facilitates data retrieval on file systems S3 and HDFS. Tables are created automatically with the correct data types and changes to the table definitions on the source are automatically propagated. Users can now use SQL access to perform data discovery with “off-the-shelf” BI Tool
Amazon Key Management Service Support
Most data stores provide data security at-rest. However in-flight data exposure is a common concern with cloud computing. With HVR 5.2’s support for client-side encryption, integrated with Amazon’s Key Management Service (KMS), data is truly encrypted end-to-end.
Metadata Manifest
Traditional relational databases follow commonly accepted transactional rules to enforce data consistency. With most data lakes built on file systems and changes commonly stored per table, a lot of the consistency between data objects is lost, and many use cases cannot handle this challenge well. MetadataManifests enable data publication at a transactionally consistent representation of the source system, even when multiple integrators deliver data in parallel.
Big Data Compare
Wide data lake adoption requires users’ trust in the data. HVR 5.2 enables programmatic data validation against the data in your data lake, even on HDFS and S3.
S3 Optimizations
Taking large volume scenarios to the next level. The data lake release introduces a number of performance enhancements to deliver data into files. With S3’s unique file handling specific enhancements let to up to 5x faster data loads into S3.