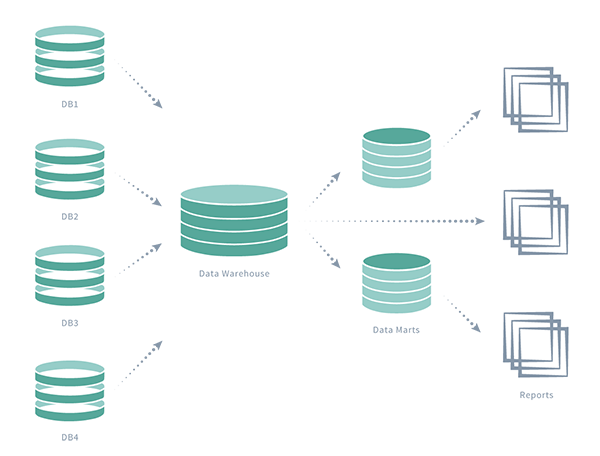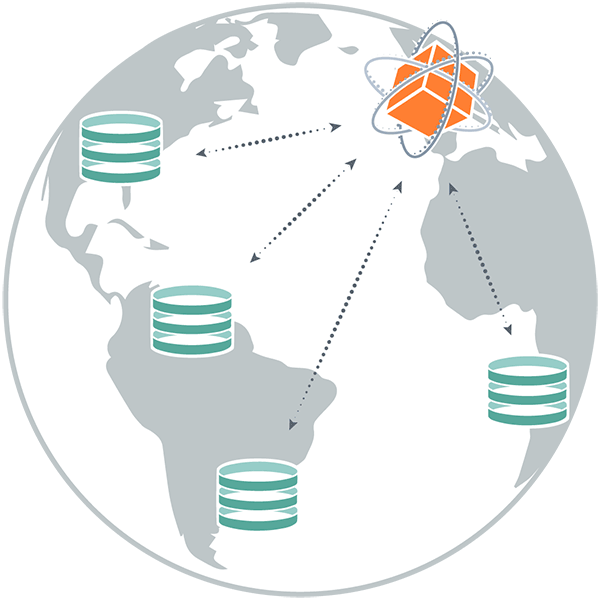
Легко консолидируйте данные в озеро данных
Все больше организаций используют озера данных в рамках своей архитектуры для обеспечения низкой стоимости и эффективности хранения больших объемов данных. Идея проста: вместо хранения данных в специально созданном хранилище данных Вы перемещаете их в озеро данных в исходном формате. Это устраняет первоначальные затраты на прием и преобразование данных. После того, как данные находятся в озере, они становятся доступны для всех в организации, для работы и анализа.
Но хотя озеро данных является эффективным решением, оно не обходится без проблем:
- Первоначальный Ввод данных из нескольких источников
- Постоянные обновления в режиме реального времени
- Перемещения больших объемов данных в озеро при задержках
We enable you to easily move your data into your lake and update your data lake in real-time. HVR’s solution includes:
- Initial data load from multiple sources to the data lake
- Log-based change data capture for real-time updates
- Compare and repair feature to ensure data accuracy
Мы позволяем Вам легко перемещать ваши данные в озеро и обновлять данные в режиме реального времени. Решение HVR включает в себя:
- Исходная загрузка данных из нескольких источников в озеро данных
- Запись изменений в базе данных для обновления в реальном времени
- Сравнить и восстановить функцию для обеспечения точности данных
Преимущества использования HVR для пополнения Вашего озера данных включают:
- Эффективная загрузка и обновление данных
- Перемещение больших объемов данных для анализа в реальном времени
- Ускорить движение данных с минимальным воздействием на системы
- Масштабировать решение для нескольких проектов и систем
Встроенная Поддержка Hive
Озеро данных обычно является начальной зоной дислокации для данных. Ученые, изучающие данные, обычно используют доступ к озеру данных для определения наборов данных, представляющих интерес, чтобы иметь возможность отобразить данные в другом, более подходящем, высокопроизводительном аналитическом механизме. Встроенная Поддержка Hive облегчает получение данных в файловых системах S3 и HDFS. Таблицы создаются автоматически с правильными типами данных, а изменения определений таблиц в источнике распространяются автоматически. Теперь пользователи могут использовать SQL access для выполнения обнаружения данных с помощью стандартного инструмента BI
Поддержка Сервиса Управления Ключами Amazon
Большинство хранилищ данных обеспечивают безопасность данных в состоянии покоя. Однако воздействие на данные в процессе перемещения является общей проблемой для облачных вычислений. Благодаря поддержке hvr 5.2 для шифрования на стороне клиента, интегрированной с сервисом управления ключами Amazon (KMS), данные действительно шифруются от начала до конца.
Манифест Метаданных
Традиционные реляционные базы данных следуют общепринятым правилам транзакций для обеспечения согласованности данных. В большинстве озер данных, построенных на файловых системах и изменениях, обычно хранящихся в таблице, большая часть согласованности между объектами данных теряется, и многие варианты использования не могут справиться с этой проблемой. Манифесты метаданных позволяют публиковать данные в транзакционно согласованном представлении исходной системы, даже если несколько интеграторов предоставляют данные параллельно.
Сравнение Больших Данных
Широкое внедрение озера данных требует доверия пользователей к данным. HVR 5.2 обеспечивает программную проверку данных в вашем озере данных, даже на HDFS и S3.
Оптимизация S3
Переход на следующий уровень сценариев больших объемов. В инструменте Data lake представлен ряд улучшений производительности для передачи данных в файлы. Благодаря уникальной обработке файлов S3 конкретные усовершенствования позволяют в 5 раз быстрее загружать данные в S3.